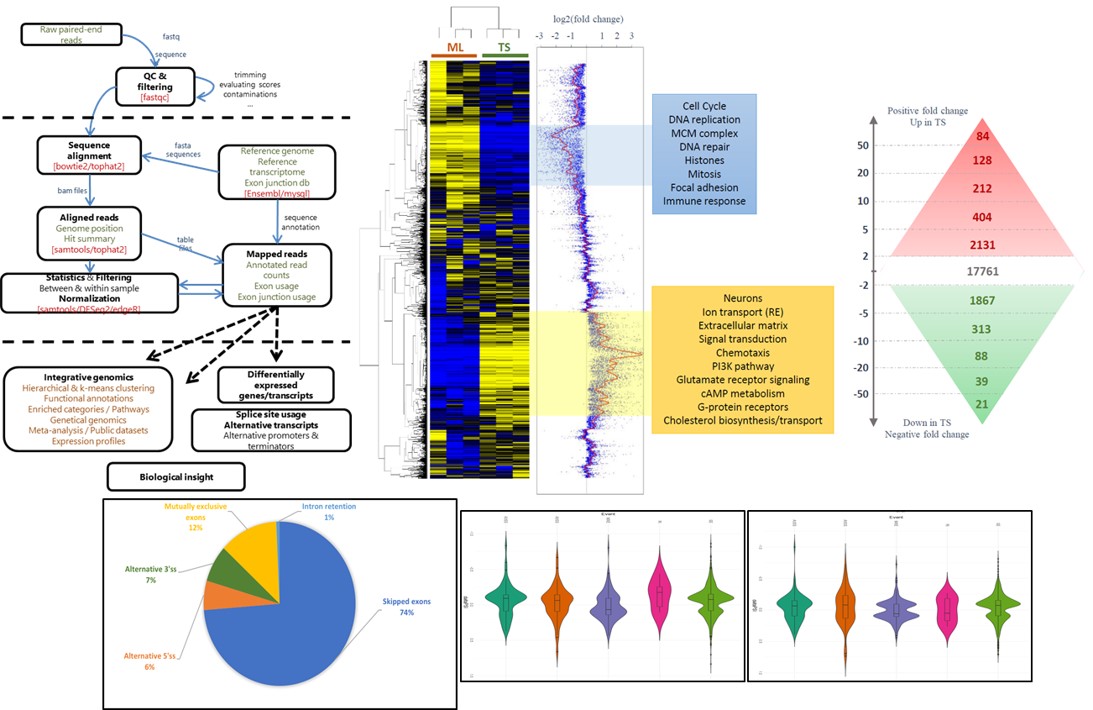
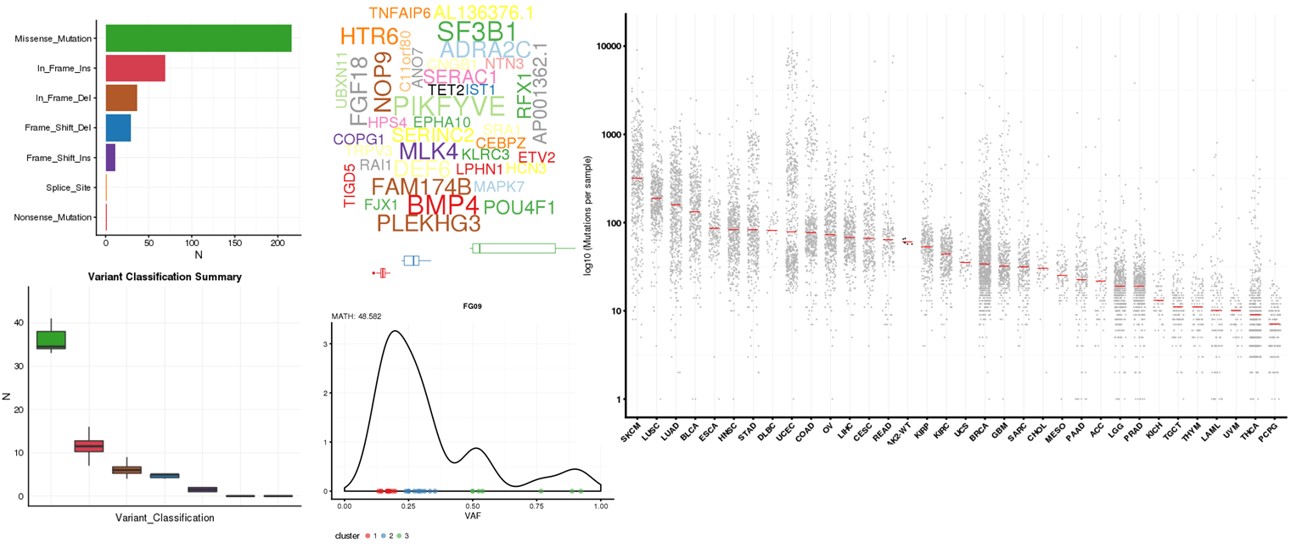
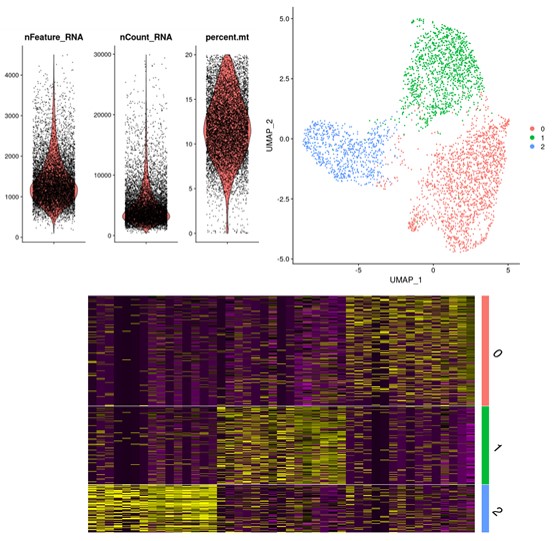
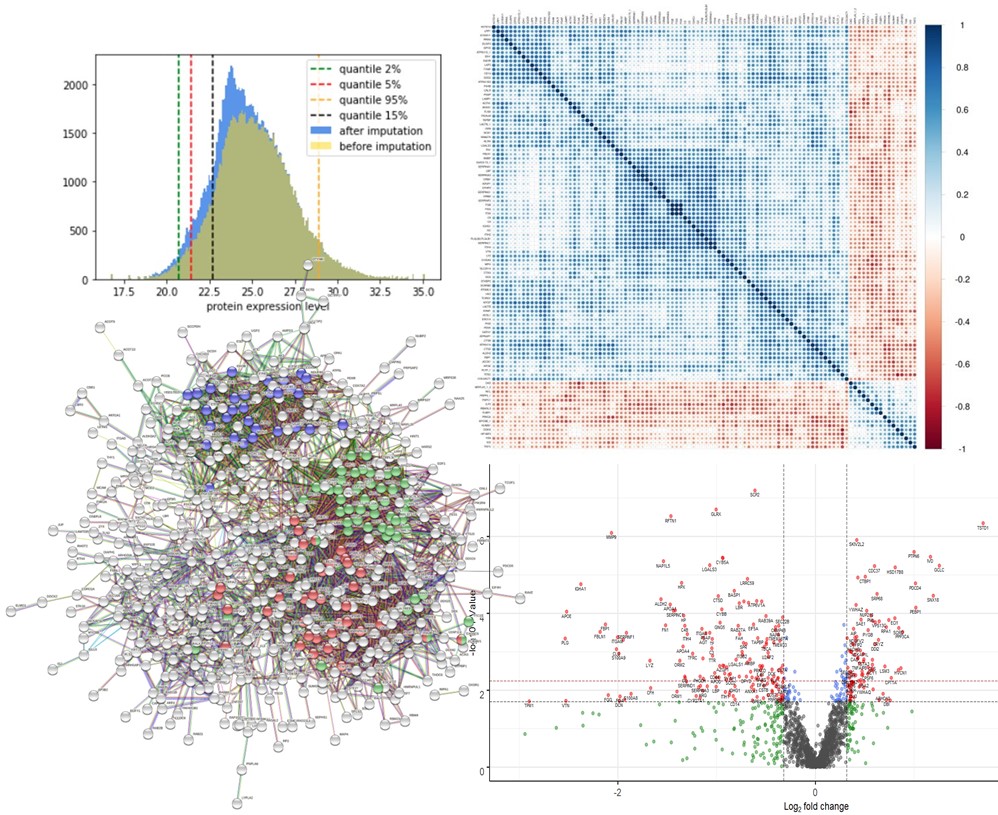

Sébastien Hergalant
Engineer (INSERM), manager

Ghislain Fiévet
Engineer, development on projects (MIGB)

Romain Piucco
PhD student / Engineer (MIGB)

Ramia Safar
Engineer (UL), functional genomics platform

Pierre Rouyer
Technician (UL), quality controls, pipelines