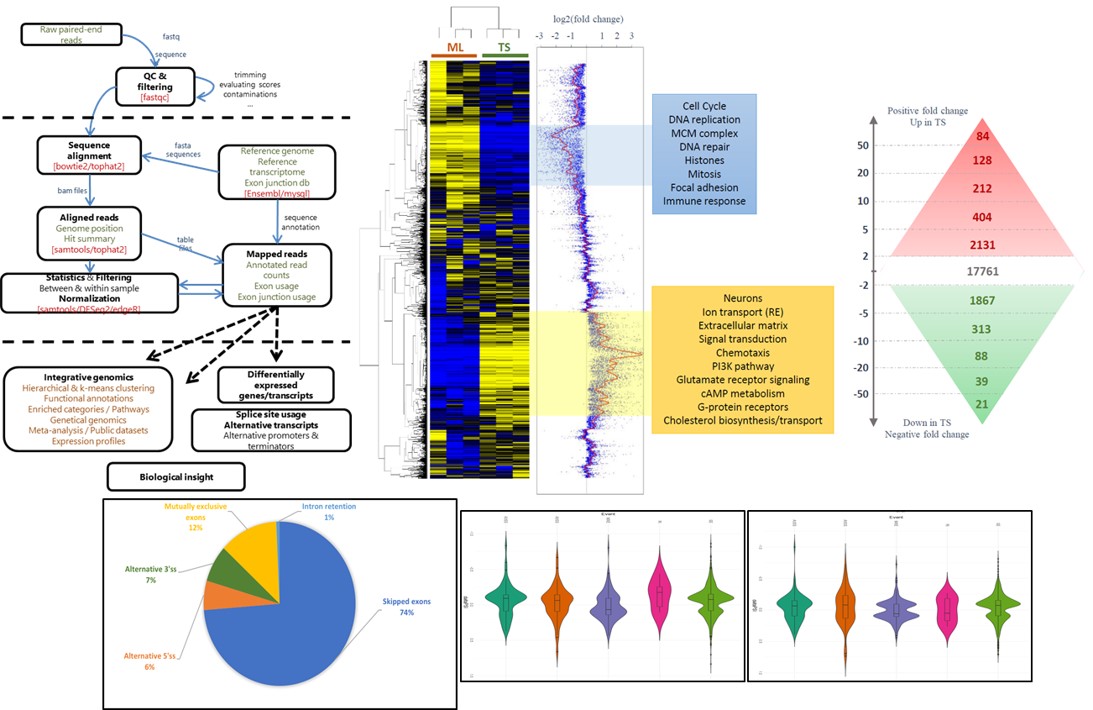
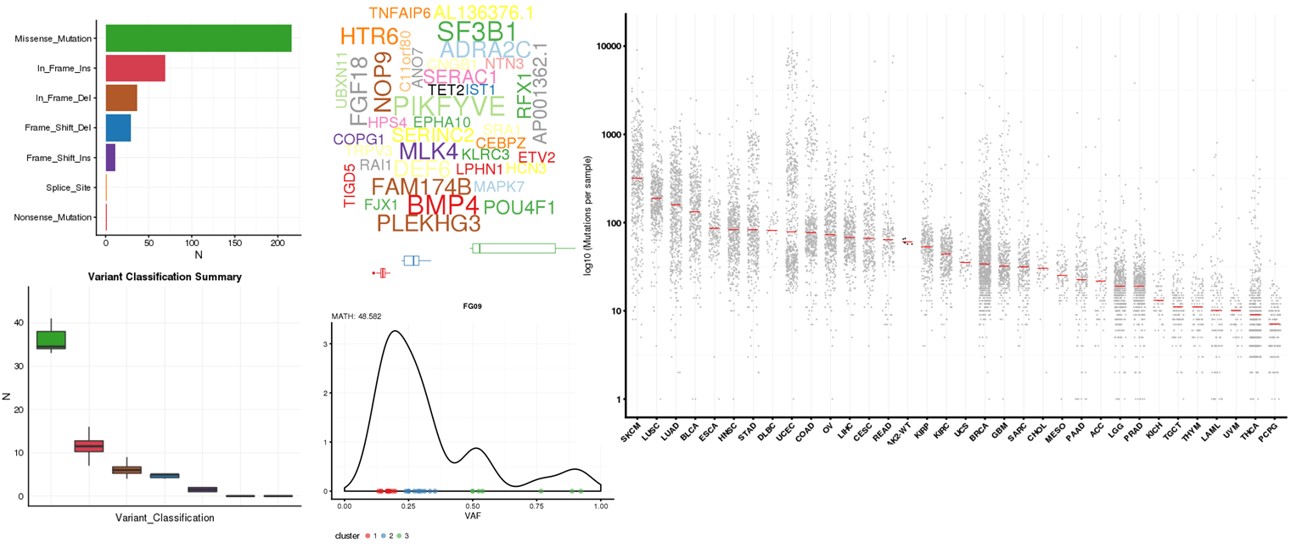
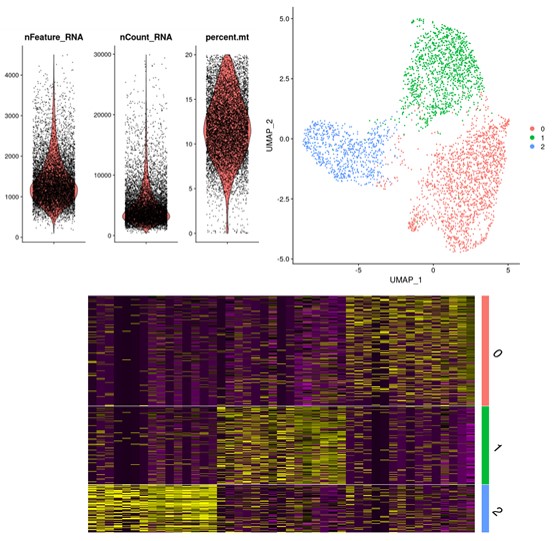
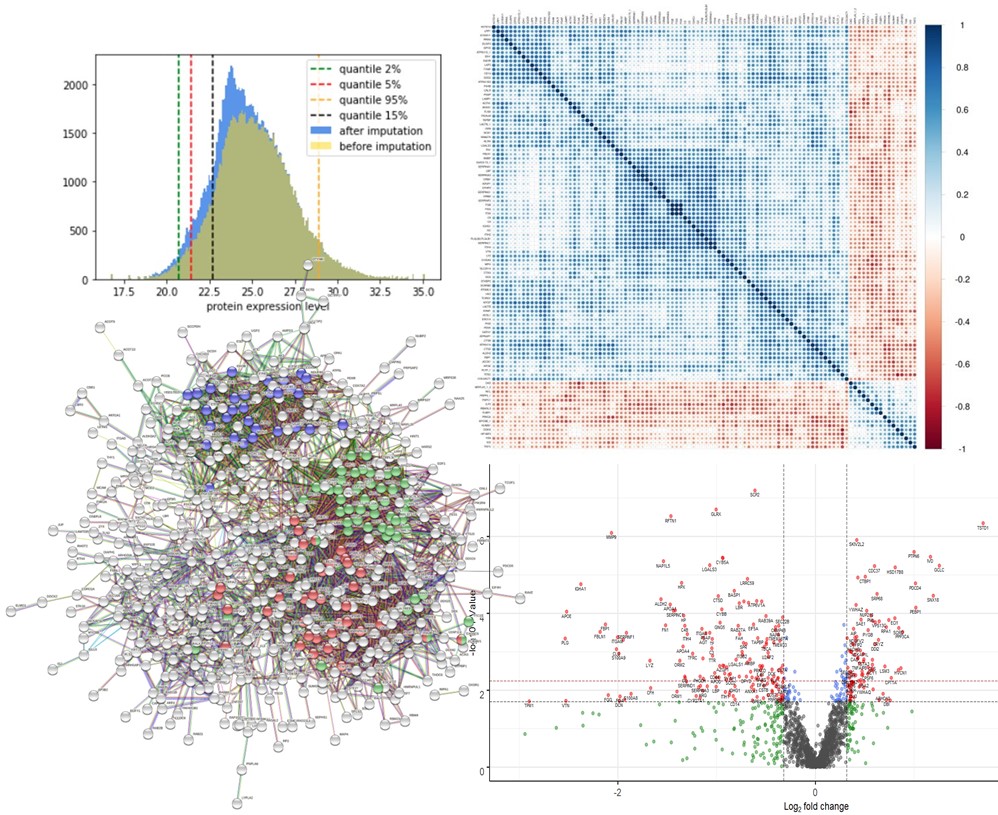
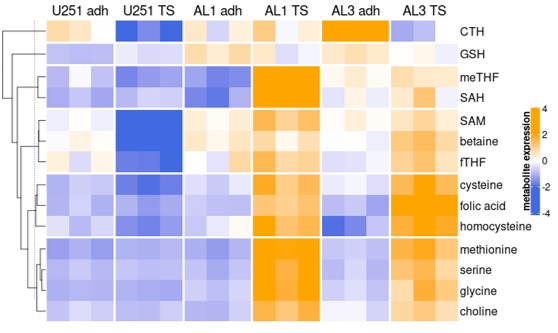
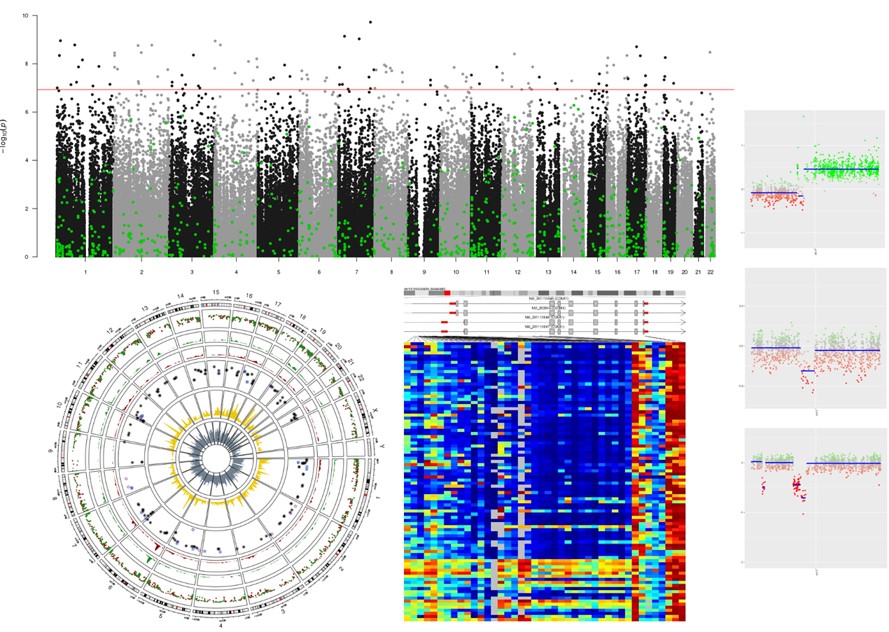
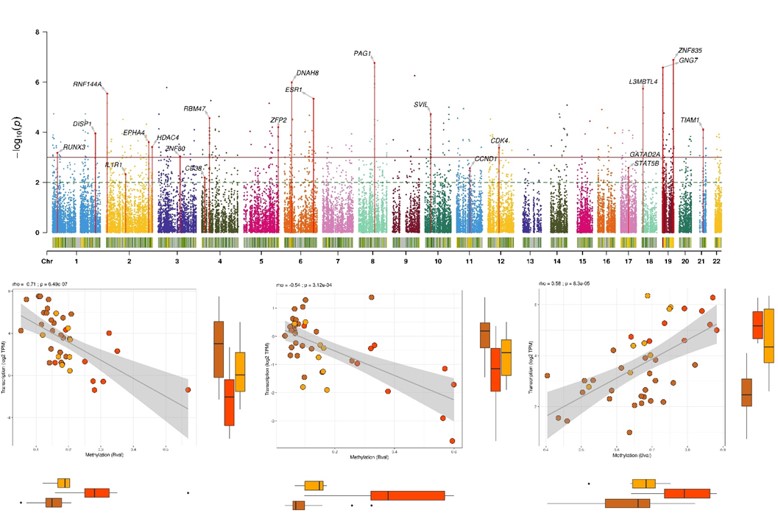
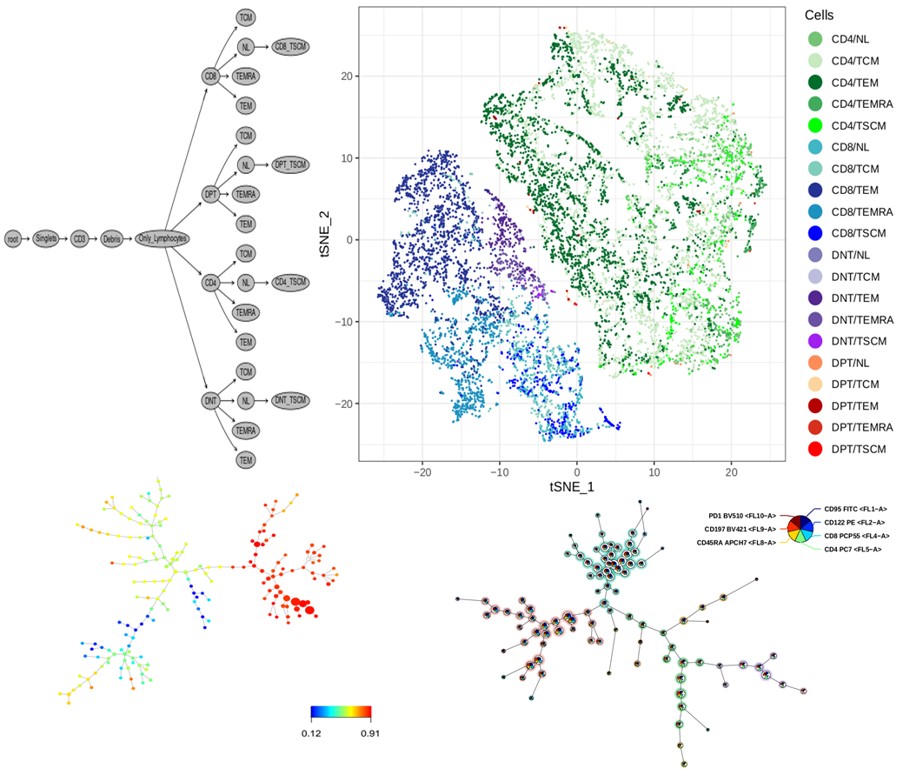

Sébastien Hergalant
Ingénieur INSERM, responsable équipe et plateforme

Ghislain Fiévet
Ingénieur CDD, développement sur projets

Romain Piucco
Doctorant, ingénieur (MIGB)

Ramia Safar
Ingénieur UL, plateforme de génomique

Pierre Rouyer
Technicien UL, contrôles qualité, pipelines